
#SQL引擎
SQL引擎是数据库核心部件之一,其核心职责是处理客户端提交的文本形式的SQL请求并执行,以及在必要时返回查询结果集给客户。
# SQL执行过程
一次完整的SQL执行过程包括解析、验证、优化和执行四个阶段,其中优化阶段又分为静态重写、生成执行计划以及动态重写三部分。
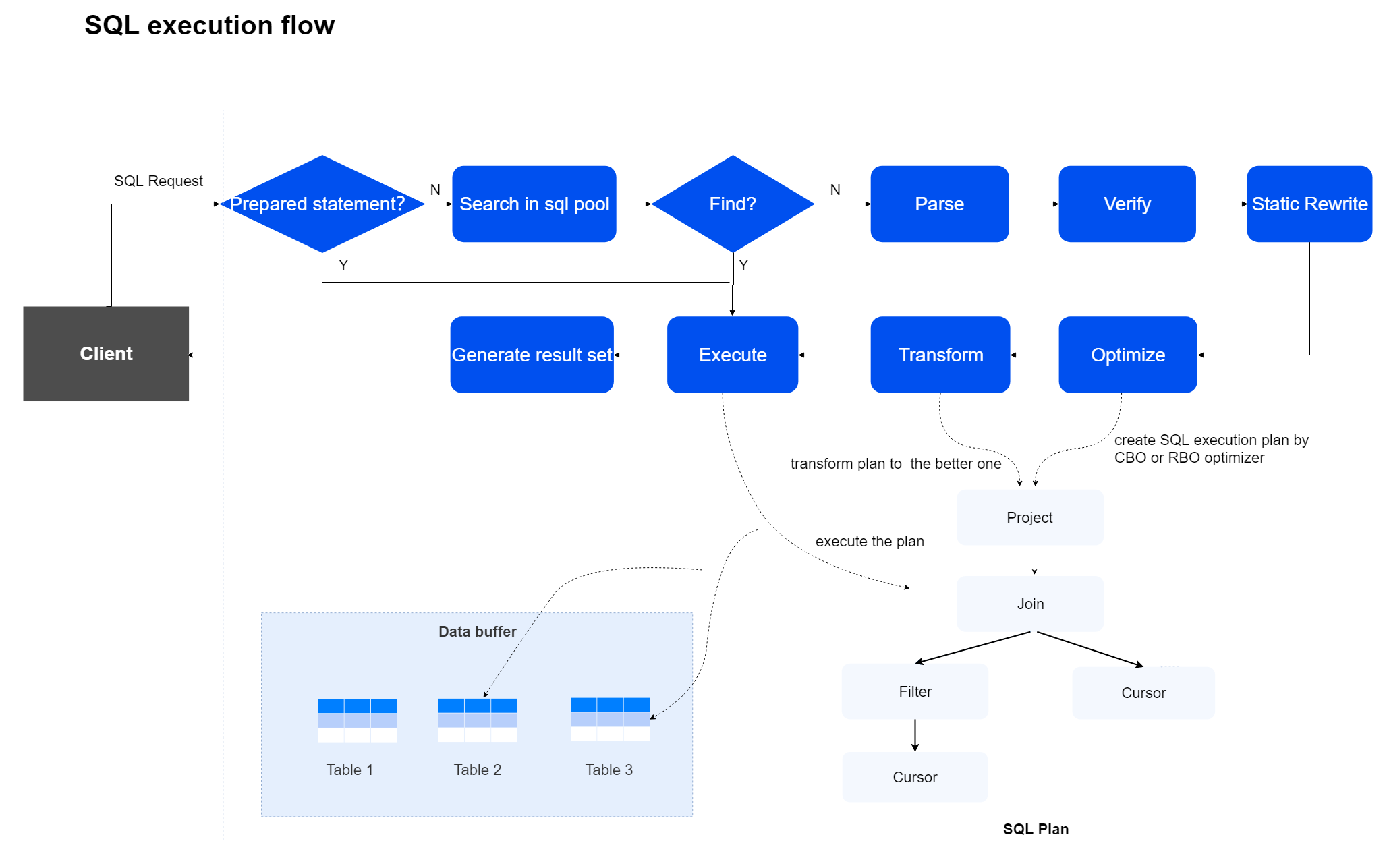
Parse阶段
解析阶段,进行词法、语法、语义解析,并生成树状的解析结果Parse Tree。
Verify阶段
校验阶段,进行用户角色权限验证、数据合法性检测、语法约束校验等,并将优化器部分工作前置,提前对Parse Tree结构体做优化变形,减少后续环节负担,为性能加速。
Optimize阶段
优化阶段,根据输入的Parse Tree生成最终的可执行的计划SQL execution plan。
Execute阶段
执行阶段,执行SQL execution plan中的算子,支持并行计算以提升效率。
# 优化器
优化器是SQL引擎的核心部件,YashanDB优化器采用CBO(Cost Based Optimizer)优化模式。
优化器根据输入的Parse Tree,尽可能生成最优执行计划,并作为输入由执行器完成后续执行过程。执行计划包含数据访问路径、表连接顺序等执行算子信息。YashanDB的CBO优化器基于统计信息,计算数据访问和处理所需要的代价,选择最优方案生成执行计划。
统计信息
主要包括表、列、索引的统计信息,例如表的行数、列的平均长度、索引包含的列数等。统计信息有动态收集、定时任务及手动触发等多种收集方式,同时,可通过并行统计、抽样统计等技术加快统计效率,为优化器提供及时更新的信息。
执行算子
算子定义了某一类具体的计算操作,是执行计划的基本组成单元。YashanDB实现了如下几种基本算子:
- 扫描算子
- 表连接算子
- 查询算子
- 排序算子
- 辅助功能算子
- PX并行执行算子
HINT
HINT是提供给用户对SQL执行计划进行干预的措施,例如指定表扫描的方式、指定执行顺序、指定并行度等,优化器将根据这些提示,结合统计信息,生成最优的执行计划。
并行度
并行度描述SQL执行时并行处理程度,可以通过参数或HINT指定并行度,干预SQL执行时采取多线程并发执行,提高SQL语句执行效率。
# 向量化计算
YashanDB支持向量化计算,核心原理是利用SIMD(Single Instruction Multiple Data)技术进行批量计算,提高计算效率。
向量化计算的内容包括:
批处理:算子间传递数据不再是单条记录,而是一批数据。
并行计算:算子并发执行。
向量化计算框架包括:
向量:算子之间传递的数据结构,由一批连续内存存储、数据类型相同、长度已知的列数据组成。
表达式:通用表达式,例如字面量(Literal)、列(Column)、函数(Function)等,通过建立计算表达式结构体,将其绑定执行所需的上下文信息、Schema生成已绑定可执行表达式,再进行计算。
执行算子:算子是SQL中将查询计划具体执行的功能单位,将输入向量数据处理后输出结果,结果也是向量数据。
# 分布式SQL执行过程
在一个分布式SQL的执行过程中,主要有如下两类实例参与:
协调实例(CN):负责对外提供接口,接收用户请求,生成分布式执行计划,向DN分发查询计划进行执行并汇总执行结果。
数据实例(DN):负责存储数据,并行执行CN下发的执行计划。
分布式SQL引擎将用户文本形式的SQL语句进行解析、验证、优化、CN向DN分发执行计划、CN/DN多节点并行执行,并最终返回查询结果集给用户。
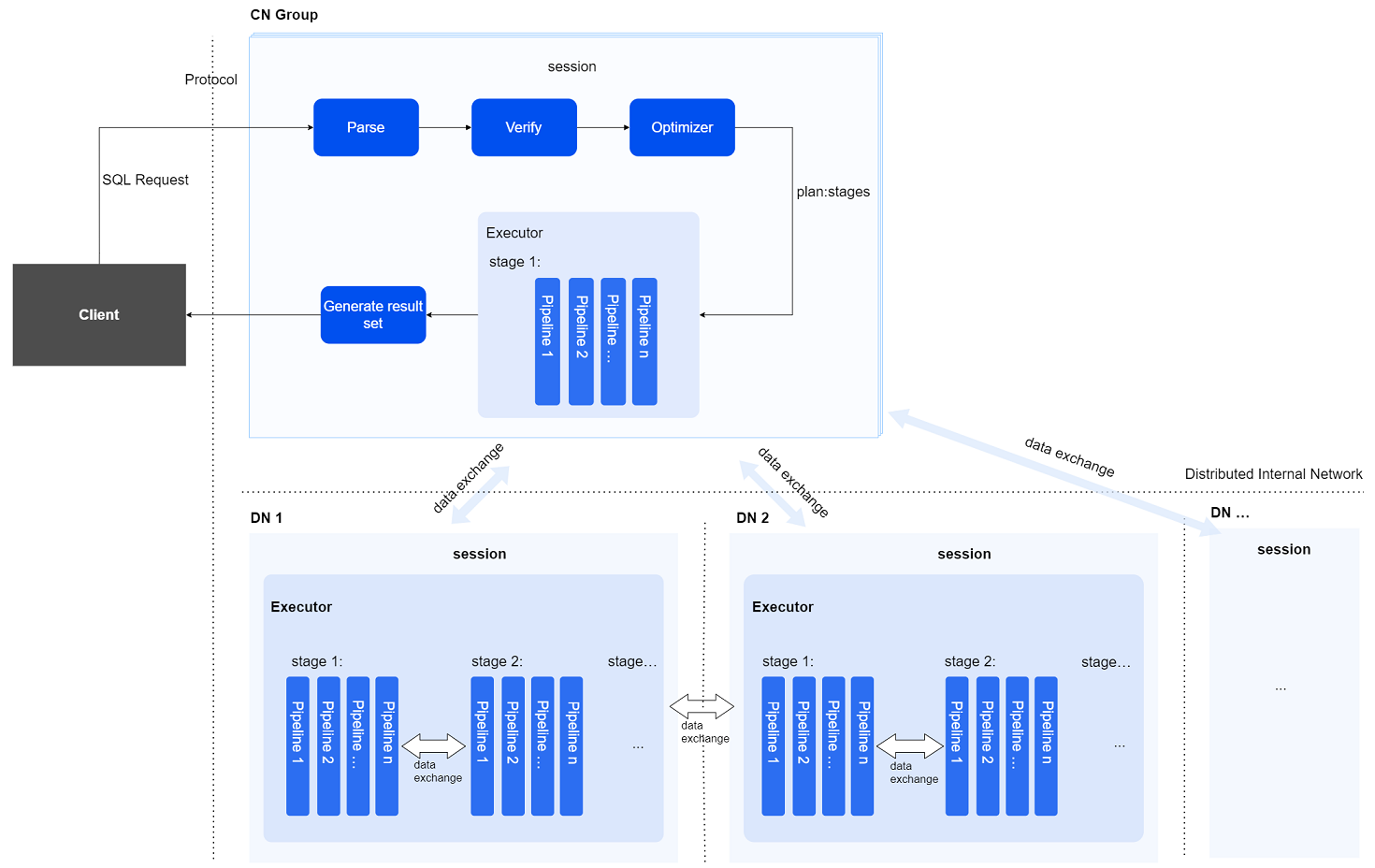
session
会话管理,用于进行节点间的管理,总管节点间执行的最终状态,以及调度节点间的执行过程。
Distributed Interconnect Network
采用异步网络通讯框架的分布式通信组件,负责节点之间的网络通信,包括CN向DN分发的执行计划,以及各节点间的数据交换。
数据交换机制
分布式数据库里的数据分片(区)存储在不同节点上,当某一个SQL计算的数据源来自于不同片(区)时,需要由特定的PX并行执行算子,将数据按指定方式,搬运到指定位置。
在一个分布式SQL的执行过程中,可能会发生如下几种情形的数据交换:
- DN上的数据向CN上汇聚成分布式SQL的查询结果。
- CN向DN发送要插入或更新的数据。
- 某个DN上的计算需使用其他DN上的数据,需要将其他DN上的数据搬运过来。
- 某个stage向同节点内的其他stage传递数据。
并行执行
YashanDB的分布式SQL执行采用典型的MPP架构,分为两级:
第一级:节点间并行
CN上的优化器根据表数据的分布信息,将一个复杂查询分为多个stage,发送到不同的DN,各DN/stage之间并行执行。
第二级:节点内并行
节点内并行执行的切分方式可以分为两类:
水平切分:CN上的优化器切分后产生的stage,在DN上可以根据数据分片信息等将一个stage放到多个pipeline执行,每个pipeline处理一个区间的数据。
垂直切分:在水平切分后,资源仍有结余,仍想继续充分利用CPU多核的能力,可以继续对stage进行垂直切分,切成多份更小的stage进行并行执行。
 下载文档
下载文档
 复制链接
复制链接




