
#大数据工具对接示例(Spark)
YashanDB支持Spark通过YashanDB JDBC驱动连接数据库并读取数据。
本文提供该功能的验证过程介绍,所使用测试环境为Windows 10。
# 环境说明
以Maven为例:
Scala version:2.12.8
SparkSql version:3.0.2
Java version:11
Maven version:3.8.6
# 创建Spark项目
本文所用IDE为IDEA,IDEA创建Scala项目时,只有sbt可选,但需要改动sbt-launch.jar,加入依赖镜像。这样构建一个项目太过于繁琐,所以本文将采用Maven项目作为连通测试。
[repositories]
local
aliyun: http://maven.aliyun.com/nexus/content/groups/public/
central: http://repo1.maven.org/maven2/
直接通过IDEA创建一个Maven项目,然后手动引入Scala。
Pom文件配置:
本文中测试工程启用的是Maven项目,而并非Scala工程推荐的sbt包管理工具,如果使用sbt包管理工具,只需要加入相应版本的依赖即可。
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
手动添加YashanDB JDBC驱动包进入项目(同Mybatis中操作描述),如果Maven私服有配置,可以直接加入Pom文件中。
# Spark连接YashanDB
Window环境下,需要指定hadoop.home.dir,否则可能出现Failed to locate the winutils binary in the hadoop binary path错误,点此下载 (opens new window)对应版本的winutils。
下例验证Spark读入数据,实现Spark与YashanDB直接连通。请将host_ip、dbname、username和password修改为实际值。
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object SparkTest {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "F:\\hadoop\\winutils-master\\hadoop-3.0.2")
val sparkConf = new SparkConf()
sparkConf.setAppName("test0001")
sparkConf.setMaster("local[2]")
val sparkSession = SparkSession.builder()
.config("spark.sql.warehouse.dir", "spark-warehouse")
.config(sparkConf)
.getOrCreate()
val jdbcDF = sparkSession.read
.format("jdbc")
.option("url", "jdbc:yasdb://host_ip:1688/dbname")
.option("driver", "com.yashandb.jdbc.Driver")
.option("user", "sys")
.option("password", "sys")
.option("dbtable", "user1")
.load()
jdbcDF.show()
}
}
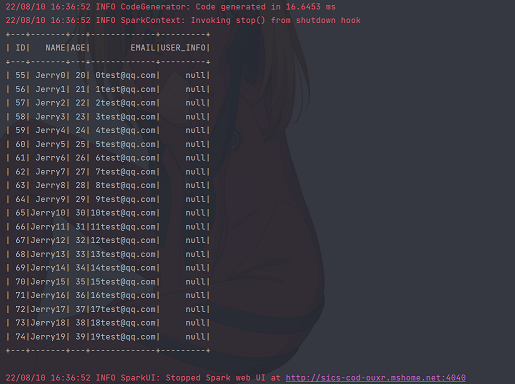
正常连通时,将会看到如下结果:
 下载文档
下载文档
 复制链接
复制链接




