
#Release Notes
# 版本信息
版本发布日期:2023年10月16日
YashanDB版本:v23.1.1
# 版本定位
YashanDB数据库v23.1版本定位为架构版本,提供全量企业级特性,支持PB级海量数据存储和大量的并发用户,支持多模数据类型、高级安全能力,支持单机主备、分布式、共享集群部署形态,配套完整数据迁移和监控运维工具,可以满足支撑各类企业应用。
同时在产品的易用性、可用性、可靠性方面做了大幅度提升。
# 特性更新
YashanDB v23.1 版本继承自 YashanDB v22.2版本全部发布的新功能,并新增了以下关键特性:
# 内核引擎增强
- 支持物化视图:支持物化视图的创建、全量刷新以及基于物化视图的查询优化
- 支持分区split操作,包括RANGE、LIST和HASH分区
- 支持二级分区,包含RANGE、LIST和HASH多种组合
- LSC表能力增强:
- 支持增删字段列
- 支持数据更新和删除
- 支持唯一性约束
- 支持SLICE内数据排序
- 支持SEGMENT CREATION DEFERRED/SEGEMENT
- 支持表空间透明压缩:支持创建透明压缩的的表空间,此表空间上的所有对象在持久化时,会进行压缩,比非压缩状态更加节省磁盘空间
- 优化代价评估模型:代价评估模型支持结合数据、硬件环境等多重因素评估更准确的执行代价
- 支持算子并行:支持全表扫描算子、分索引扫描算子、分区执行算子等并行
- 支持ipv6协议:YashanDB及相关产品组件(yasql、yasom、imp/exp等)均已支持 IPv6 协议,支持 IPv4 和 IPv6 网络接口的 TCP/IP 连接。
# SQL引擎增强
- 基础数据类型增强:支持NCHAR、NVARCHAR、NCLOB等数据类型及相关函数,字符串长度规格提升至32000字符
- 支持空间数据类型(GIS):支持原生矢量空间数据类型和空间索引,以及符合OGC SFSQL及ISO SQL/MM标准的空间函数
- JSON类型增强:支持扩展JSON数据类型,JSON数据存储规则提升至32MB,支持JSON相关函数
- 支持DBLink:支持通过YashanDB连接YashanDB和Oracle数据库,支持查询和修改操作;同时支持通过Oracle数据库反向连接到YashanDB数据库
- 外置C存储过程:支持C语言的外置存储过程
- 新增内置高级包:新增UTL_FILE、DBMS_MVIEW和DBMS_RESOURCE_MANAGER内置高级包
- plugin-in程序包优化:数据库实例支持加载和使用第三方开发者提供的程序包中的函数和存储过程
# 高可用
- 自动选举能力增强:新增支持在一主一备模式下自动选举能力,支持主备部署形态下故障自动恢复
- 故障识别增强:支持主节点在没有收到多数节点心跳响应时主动降备,提前识别故障,预防脑裂
- 故障透明切换:支持C驱动、JDBC驱动的故障透明切换能力
# 驱动
- C驱动增强:支持CURSOR类型,支持stream传输协议,优化LOB发送协议
- JDBC增强:支持hibernate方言包、TAF接口、新增支持JSON和CURSOR类型
# 工具
- 可视化安装部署:支持单机、分布式、共享集群的可视化部署
- 运维工具增强:支持对节点运行状态、健康状态、错误日志、资源占用、慢SQL、锁等待等状态的巡检;支持备份策略的管理和配置以及备份流水和详情展示
- 导数工具增强
- imp/exp工具增强:支持自定义数据类型、LIBRARY、二级分区、物化视图和DBLink导入导出;支持To User模式和元数据导入导出模式
- yasldr工具增强:支持并行导入、大对象导入等;优化导入性能;支持导入报错跳过,记录异常数据等易用性功能
# 共享集群
- 支持基于共享存储,采用融合内存技术的2节点多写多读集群
- 支持全局资源管理、全局数据块管理、全局锁管理
- 支持管理物理磁盘、裸设备,支持故障组、磁盘组、多副本、冗余等管理能力
- 支持管理崖山文件系统、数据库实例资源,提供配置资源、启停、监控、仲裁等服务
- 支持集群内任意节点、实例在线故障场景下的故障自动检测、自动恢复
# 分布式
- 支持基于有界计算理论创新的数据查询模型
- 扩缩容能力增强:
- 支持数据节点组(DN)在线扩缩容
- 支持协调节点组(CN)扩容
- 支持数据节点组(DN)和管理节点组(MN)的组内增删节点
- 语法扩展:
- 支持大LOB类型
- 存储过程支持匿名块
- 支持带子查询的DML语句
- 支持INSERT ON DUPLICATE KEY UPDATE语法
- 支持SAVEPOINT
- 诊断能力增强:autotrace支持SQL执行的统计信息详细展示
- 稳定性提升:支持多点故障,连续故障,磁盘,资源类故障等应对与恢复
# 兼容性变更
# 行为变更
分布式形态下,不再支持通过distributed by语法指定数据分布规则
分布式形态下,分区表的一级分区必须指定为哈希分区,不指定分区的情况下默认创建哈希分区,如要创建范围和列表分区的分区表,请使用二级分区语法。后续版本将完善支持范围和列表分区规则
# 视图&系统表变更
| 视图名称 | 变更类型 | 描述 |
|---|---|---|
| ALL_DB_LINKS | 新增 | 显示当前用户可访问的所有数据库链接信息 |
| ALL_IND_SUBPARTITIONS | 新增 | 显示当前用户可访问的所有索引子分区信息 |
| ALL_LOB_SUBPARTITIONS | 新增 | 显示当前用户可访问的所有LOB子分区信息 |
| ALL_MVIEWS | 新增 | 显示当前用户可访问的所有物化视图信息 |
| ALL_SUBPART_KEY_COLUMNS | 新增 | 显示当前用户可访问的所有的二级分区键列信息 |
| ALL_SUBPARTITION_TEMPLATES | 新增 | 显示当前用户可访问的所有子分区模板信息 |
| ALL_TAB_SUBPARTITIONS | 新增 | 显示当前用户可访问的所有子分区信息 |
| DBA_DB_LINKS | 新增 | 显示所有数据库链接信息 |
| DBA_IND_SUBPARTITIONS | 新增 | 显示所有组合分区索引的每个二级分区信息 |
| DBA_LOB_SUBPARTITIONS | 新增 | 显示所有LOB对象的二级分区信息 |
| DBA_MVIEWS | 新增 | 显示数据库中所有物化视图基本信息 |
| DBA_SUBPART_KEY_COLUMNS | 新增 | 显示数据库中所有二级分区对象的分区键列信息 |
| DBA_SUBPARTITION_TEMPLATES | 新增 | 显示所有子分区模板的信息 |
| DBA_TAB_SUBPARTITIONS | 新增 | 显示所有子分区信息 |
| ROLE_ROLE_PRIVS | 新增 | 显示当前用户拥有的角色的角色信息 |
| USER_DB_LINKS | 新增 | 显示当前用户可访问的所有数据库链接信息 |
| USER_IND_SUBPARTITIONS | 新增 | 显示当前用户可访问的所有索引子分区信息 |
| USER_LOB_SUBPARTITIONS | 新增 | 显示当前用户可访问的所有LOB子分区信息 |
| USER_MVIEWS | 新增 | 显示当前用户物化视图信息 |
| USER_ROLE_PRIVS | 新增 | 显示当前用户的角色信息 |
| USER_SUBPART_KEY_COLUMNS | 新增 | 显示当前用户可访问的所有的二级分区键列信息 |
| USER_SUBPARTITION_TEMPLATES | 新增 | 显示当前用户可访问的所有子分区模板信息 |
| USER_TAB_SUBPARTITIONS | 新增 | 显示当前用户可访问的所有子分区信息 |
| V$BUFFER_CONTROL | 新增 | 显示数据库缓存区页面控制信息 |
| V$CHANNEL_PERF | 新增 | 显示当前会话各1对1Channel的传输性能统计信息 |
| V$CLUSTER_MESSAGE | 新增 | 显示共享集群消息池中待处理的消息信息 |
| V$CLUSTER_MESSAGE_POOL | 新增 | 显示共享集群消息池的概况 |
| V$CLUSTER_MESSAGE_STAT | 新增 | 显示共享集群消息交互统计信息 |
| V$CLUSTER_TASK_STAT | 新增 | 显示共享集群后台线程的相关统计信息 |
| V$CLUSTER_TASK_INFO | 新增 | 显示CM模块存储的TASK INFO信息 |
| V$CPUSTAT | 新增 | 显示单机,主备和分布式集群中所有节点的资源管理汇总信息 |
| V$DATA_CONNECTION | 新增 | 显示分布式集群中当前节点已创建的会话内连接信息 |
| V$DISKCACHE | 新增 | 展示磁盘缓存的状态信息 |
| V$FIXED_TABLE | 新增 | 显示当前实例中每个固定表的详细信息 |
| V$FIXED_VIEW_DEFINITION | 新增 | 显示当前实例中每个固定视图的定义信息 |
| V$GLS_LOCK | 新增 | 显示共享集群全局锁情况消息 |
| V$GRC_DHTRULE | 新增 | 显示共享集群中Master资源的Hash分布情况消息 |
| V$GRC_PASTCOPY | 新增 | 显示PAST COPY BLOC信息 |
| V$GRC_RESOURCE | 新增 | 显示共享集群全局资源情况消息 |
| V$RESOURCE_REQUEST | 新增 | 显示资源当前等待处理的消息 |
| V$SESSION_ROLES | 新增 | 显示当前登录USER的所有生效角色消息 |
| V$SQL_PLAN_TRACE | 新增 | 仅供AUTOTRACE功能使用,记录SQL每个执行算子的数据统计信息 |
| V$SQL_TRACE | 新增 | 仅供AUTOTRACE功能使用,记录SQL执行产生的统计信息 |
| V$TASK | 新增 | 显示当前执行和等待的任务信息 |
| V$TEMP_EXTENT_POOL | 新增 | 显示检测临时属性的表空间,其extent分配情况消息 |
| V$YFS_DISK | 新增 | 显示 YFS 磁盘(Disk)信息 |
| V$YFS_DISKGROUP | 新增 | 显示 YFS 磁盘组(Diskgroup)信息 |
| V$YFS_FAILGROUP | 新增 | 显示 YFS 故障组(Failgroup)信息 |
| V$YFS_FILE | 新增 | 显示 YFS文件信息 |
| DBA_DATA_BUCKETS | 修改 | 新增BUCKET_NAME字段,表示LSC表空间的Databucket(数据桶)的Databucket名称; 移除BUCKET_URL字段 |
| DBA_JOBS | 修改 | 新增RUNNING_INSTANCE字段,表示后台执行JOB的实例ID |
| DBA_LOBS | 修改 | 新增COMPOSITE字段,表示LOB分区是否存在二级分区 |
| DBA_LSC_SLICE_STAT | 修改 | 新增SORTED_SLICES字段,表示所有LSC表对象的已排序的Slice个数; 新增COMPACTED_SLICES字段,表示所有LSC表对象的已合并的Slice个数 |
| DBA_PART_TABLES | 修改 | 新增SUBPARTITIONING_TYPE字段,表示分区表的子分区类型; 新增SUBPARTITIONING_KEY_COUNT字段,表示分区表的子分区键包含的列数量 |
| DBA_SCHEDULER_JOBS | 修改 | 新增INSTANCE_ID字段,表示集群中可以执行JOB的实例ID。默认值是0,表示可以在任意实例执行; 新增RUNNING_INSTANCE字段,表示后台执行JOB的实例ID,非RUNNING状态显示为0 |
| DBA_SORT_TABLES | 修改 | 新增SORT_MCOL字段,表示是否排序 |
| DBA_TABLES | 修改 | 新增TRANSFORM字段,表示LSC表是否允许可变数据转换为不可变数据; 新增COMPACT字段,表示LSC表是否允许不可变数据进行合并;移除ENABLE_XFMR字段 |
| DBA_TABLESPACES | 修改 | 新增COMPRESSED字段,表示表空间是否压缩 |
| V$ARCHIVE_DEST_STATUS | 修改 | 新增DEPOSIT_THREAD#字段,表示托管实例编号 |
| V$ARCHIVED_LOG | 修改 | 新增THREAD#字段,表示实例编号 |
| V$CM_CLUSTER_INFO | 修改 | 新增NEXT_GROUP_ID字段,表示集群中下一个组的Id; 新增MAX_ENDPOINT字段,表示集群中Endpoint最大值 |
| V$CM_GROUP_INFO | 修改 | 新增NEXT_NODE_ID字段,表示组中下一个节点的Id |
| V$DATABASE | 修改 | 新增SWITCHOVER_STATUS字段,表示主备角色切换的状态 |
| V$DATABUCKET | 修改 | 新增NAME、SLOT、USED_SIZE、MAX_SIZE、READONLY字段,表示LSC表空间的Databucket(数据桶)文件信息 |
| V$DATAFILE | 修改 | 新增DISK_BYTES字段,表示物理磁盘的占用大小(单位字节) |
| V$ELECTION | 修改 | 新增PEERS字段,表示当前节点的节点组成员 |
| V$INSTANCE | 修改 | 新增INSTANCE_ROLE字段,表示当前实例角色 |
| V$LOGFILE | 修改 | 新增THREAD#字段,表示实例编号 |
| V$LSC_SLICE_STAT | 修改 | 新增SORTED字段,表示LSC表的SLICE是否排序; 新增COMPACTED字段,表示LSC表的SLICE是否合并 |
| V$REPLICATION_STATUS | 修改 | 新增THREAD#字段,表示实例编号; 新增TIME_SINCE_LAST_MSG字段,表示从备机收到最后一条消息,到现在经过的时间,单位秒 |
| V$SESSION | 修改 | 新增IS_HEARTBEAT字段,表示会话是否为心跳会话 |
| V$SQL | 修改 | 修改APPLICATION_WAIT_TIME、CONCURRENCY_WAIT_TIME、CLUSTER_WAIT_TIME、USER_IO_WAIT_TIME、PLSQL_EXEC_TIME、CPU_TIME和ELAPSED_TIME字段的单位由毫秒为微秒 |
| V$SQL_PLAN_STATISTICS | 修改 | 新增BLOCK_RECEIVED字段,表示集群下从其他节点获取的最新页面的次数; 新增CR_BLOCK_RECEIVED字段,表示集群下从其他节点获取的CR页面的次数; 新增LOCAL_GRANTS字段,表示集群下本节点授权加载页面的次数; 新增REMOTE_GRANTS字段,表示集群下其他节点授权授权加载页面的次数; 新增LOCAL_UPGRADES字段,表示集群下本节点授权页面锁升级的次数; 新增REMOTE_UPGRADES字段,表示集群下其他授权页面锁升级的次数; 修改LAST_ELAPSED、ELAPSED_TIM字段的单位由毫秒为微秒 |
| V$SQLAREA | 修改 | 修改APPLICATION_WAIT_TIME、CONCURRENCY_WAIT_TIME、CLUSTER_WAIT_TIME、USER_IO_WAIT_TIME、PLSQL_EXEC_TIME、CPU_TIME和ELAPSED_TIME字段的单位由毫秒为微秒 |
| V$SQLSTATS | 修改 | 新增BLOCK_RECEIVED字段,表示集群下从其他节点获取的最新页面的次数; 新增CR_BLOCK_RECEIVED字段,表示集群下从其他节点获取的CR页面的次数; 新增LOCAL_GRANTS字段,表示集群下本节点授权加载页面的次数; 新增REMOTE_GRANTS字段,表示集群下其他节点授权授权加载页面的次数; 新增LOCAL_UPGRADES字段,表示集群下本节点授权页面锁升级的次数; 新增REMOTE_UPGRADES字段,表示集群下其他授权页面锁升级的次数; 修改CPU_TIME、ELAPSED_TIME、APPLICATION_WAIT_TIME、CONCURRENCY_WAIT_TIME、CLUSTER_WAIT_TIME、USER_IO_WAIT_TIME和PLSQL_EXEC_TIME字段的单位由毫秒为微秒 |
| V$TABLESPACE | 修改 | 新增COMPRESSED字段,表示是否为压缩表空间 |
| V$TRANSACTION | 修改 | 移除START_SCN字段 |
# 系统参数变更
| 配置参数 | 修改类型 | 描述 |
|---|---|---|
| CGROUP_FLAG | 新增 | 表示当前节点资源管理功能是否开启 |
| CGROUP_ROOT_DIR | 新增 | 表示当前节点Cgroup的安装路径 |
| CLUSTER_DATABASE | 新增 | 表示在创建数据库时,指定当前数据库是否为共享集群数据库 |
| CLUSTER_INTERCONNECT | 新增 | 表示在共享集群数据库中,设置集群实例间的通信地址 |
| CLUSTER_RECONNECT_TIME | 新增 | 表示在共享集群数据库中,指定集群场景下,内部网络重连时间,单位为毫秒 |
| CLUSTER_SERVICE | 新增 | 表示在共享集群数据库中,数据库实例与集群管理服务的通信文件路径 |
| COLUMNAR_VM_SWAP_SIZE | 新增 | 表示指定列存计算数据文件使用的磁盘大小。当列存计算中,排序,物化,join等涉及的数据量较多时,建议调大此参数 |
| DATA_TRANSFORMER_ENABLED | 新增 | 表示设置LSC表数据是否允许后台自动进行Transformer操作 |
| DBWR_FLUSH_NEIGHBORS_COUNT | 新增 | 表示指定数据库刷磁盘时进行脏块合并时寻找邻居脏块的个数,设置为1表示关闭脏块合并 |
| DEFAULT_MCOL_TTL | 新增 | 表示LSC表可变数据的生命周期,单位为秒。建议使用默认值 |
| ENABLE_ARCH_DATA_IGNORE_BACKUP | 新增 | 表示ARCH_DATA归档清理时,忽略备份操作,当文件发送给全部备机后,清理该归档文件。如果不需要备份,请将该参数设置TRUE |
| ENABLE_DISKCACHE | 新增 | 表示是否启用磁盘缓存 |
| GCS_TASK_COUNT | 新增 | 表示在共享集群数据库中,设置共享集群后台处理页面资源相关请求的线程数 |
| GLS_TASK_COUNT | 新增 | 表示在共享集群数据库中,设置共享集群后台处理DDL和锁资源相关请求的线程数 |
| GRC_TASK_COUNT | 新增 | 表示在共享集群数据库中,设置共享集群后台处理资源请求和排队的线程数 |
| HA_ELECTION_LEADER_LEASE_ENABLED | 新增 | 表示在开启自选举场景下,是否开启主节点在未收到多数派备机心跳响应时主动降备的功能 |
| INSTANCE_NAME | 新增 | 表示当前运行实例的名称 |
| INTERCONNECT_LINKS | 新增 | 表示共享集群实例间通信的通道数量,所有实例需保持一致 |
| INTERCONNECT_MESSAGE_POOL | 新增 | 表示共享集群的实例间通信消息池的配置信息 count表示每个pool可以容纳消息的数量; size表示pool中一条消息的最大值,单位Byte。 每个pool的总大小等于count*size,固定四组pool,需要配置每个pool的size不一样。设置参数值时,最后一组pool后的分号可缺省,亦可选择保留 |
| INTERCONNECT_RECEIVE_TIMEOUT | 新增 | 表示ICS接收消息超时时间,单位为秒,设置为0表示无限等待(不超时) |
| QUERY_REWRITE_ENABLED | 新增 | 表示是否使用物化视图的查询重写 FALSE(默认值)表示不使用,TRUE表示启用优化器的查询重写功能,并根据优化器的Cost成本在原语句与重写语句之间选择更优计划。FORCE表示启用优化器的查询重写功能,并指示优化器强制使用物化视图重写查询 |
| RESOURCE_MANAGER_PLAN | 新增 | 表示当前节点Cgroup计划名称 |
| SCOL_CACHEABLE_SCAN_ROWS | 新增 | 表示LSC表使用稳态数据缓存区的最大扫描记录数,如果查询计划评估扫描记录数超过该值,该扫描读取的数据不会写入稳态数据缓冲区 |
| SCOL_DISK_CACHEABLE_SCAN_ROWS | 新增 | 表示LSC表使用磁盘缓存的最大扫描记录数,如果查询计划评估扫描记录数超过该值,该扫描读取的数据不会写入磁盘缓存 |
| SCOL_SLICE_ROWS | 新增 | 表示指定静态Slice文件的数据上限,后台的Slice文件合并会根据此配置进行,如果希望数据库内的Slice文件更大,可调大此配置,另外,此配置项只允许调大 |
| SESSION_MAX_OPEN_FILES | 新增 | 表示指定会话中UTL_FILE系统包最多可以打开的文件数 |
| YASFS_DATA_DIR | 新增 | 表示指定共享集群模式下默认数据文件位置,目前必须为 YFS 绝对路径,即以 '+' 开头,例如+DiskGroup/full/path/only |
| DATA_TRANSFORMERS | 废弃 | 从v23.1版本起,该系统参数被废弃,当前数据库会跟进内部压力分配后台转换线程进行稳态数据转换 |
# 升级说明
主备部署形态支持v22.2版本升级到v23.1版本。
分布式部署形态支持v22.2及以上版本升级到v23.1版本。
# 周边配套
YashanDB数据库v23.1版本推荐使用的平台工具版本如下:
| 组件 | 配套版本 |
|---|---|
| YashanDB JDBC 驱动程序(JDBC) | v1.5 |
| YashanDB ODBC 驱动程序(ODBC) | v23.1 |
| YashanDB C 驱动程序(C) | v23.1 |
| YashanDB C# 驱动程序(ADO.NET) | v1.5 |
| YashanDB Python 驱动程序(Python) | v1.0 |
| YashanDB 客户端(yasql) | v23.1 |
| YashanDB 监控运维工具(YCM) | v23.2.1 |
| YashanDB 部署工具 (yasboot) | v23.1 |
# 性能测试
# YashanDB数据库单机部署的TPC-C性能测试
# 硬件环境
| 设备类型 | 品牌类别 | 配置 | 数量 |
|---|---|---|---|
| 物理机 | 华为服务器2288H V5 | CPU物理核数: 26 CPU逻辑核数:104 内存: 376GB 硬盘:2个nvmeSSD盘,每个2.9T | 1台 |
# 软件环境
| 类别 | 软件名称 | 版本 |
|---|---|---|
| 操作系统 | Centos | CentOS Linux release 7.9.2009 (Core) |
| 数据库 | YashanDB | v23.1 |
| 测试工具 | BenchmarkSQL | BenchmarkSQL-5.0 |
# 数据库参数配置
DATA_BUFFER_SIZE=200G
_DATA_BUFFER_PARTS=8
VM_BUFFER_SIZE=25G
VM_BUFFER_PARTS=8
REDO_BUFFER_SIZE=64M
REDO_BUFFER_PARTS=8
WORK_AREA_POOL_SIZE=2G
UNDO_RETENTION=30
UNDO_SHRINK_ENABLED=FALSE
WORK_AREA_HEAP_SIZE=2M
CHECKPOINT_TIMEOUT=1000000000
CHECKPOINT_INTERVAL=128M
MAX_WORKERS=300
SHARE_POOL_SIZE=2G
# TPC-C配置
newOrderWeight=45
paymentWeight=43
orderStatusWeight=4
deliveryWeight=4
stockLevelWeight=4
# 测试总结
YashanDB数据库v23.1版本单机部署在Linux系统上性能稳定,tpmC (NewOrders)值达到152W。
| 仓数 | 并发数 | 测试时长 | tpmC (NewOrders) |
|---|---|---|---|
| 1000 | 256 | 10分钟 | 152W |
# YashanDB数据库共享集群部署的TPC-C性能测试
# 硬件环境
| 设备类型 | 设备型号 | 详细参数 | 数量 |
|---|---|---|---|
| 物理机(服务端) | 超聚变服务器2288H V6 | CPU:Intel(R) Xeon(R) Gold 5320 CPU @ 2.20GHz CPU核数:26 内存:376GB | 2台 |
| 物理机(客户端) | ThinkSystem SR650 V2 | CPU:Intel(R) Xeon(R) Gold 6338 CPU @ 2.00GHz CPU核数:32 内存:377GB | 1台 |
# 存储配置
| 设备类型 | 硬盘类型 | 详细参数 | 数量 |
|---|---|---|---|
| 共享存储 | SSD | 硬盘数量:4块 控制器:双控制器 缓存容量:32GB * 2 物理核心:Kunpeng 920 18core 2.1GHz* 2 硬盘域:4块硬盘组成一个硬盘域 存储池:把硬盘域的所有空间划分为一个存储池,RAID模式为RAID 0,分条深度(128KB),划分为3个lun | 硬盘数量:3块 (容量3TB) |
# 软件环境
| 类别 | 软件名称 | 版本 |
|---|---|---|
| 操作系统 | Centos | CentOS Linux release 7.9.2009 (Core) |
| 数据库 | YashanDB | v23.1 |
| 测试工具 | BenchmarkSQL | BenchmarkSQL-5.0 |
# 数据库参数配置
DATA_BUFFER_SIZE=200G
VM_BUFFER_SIZE=25G
VM_BUFFER_PARTS=8
REDO_BUFFER_SIZE=64M
REDO_BUFFER_PARTS=8
WORK_AREA_POOL_SIZE=2G
UNDO_RETENTION=3
UNDO_SHRINK_ENABLED=FALSE
WORK_AREA_HEAP_SIZE=2M
CHECKPOINT_TIMEOUT=1000000000
CHECKPOINT_INTERVAL=150G
MAX_WORKERS=600
SHARE_POOL_SIZE=10G
COMMIT_LOGGING = BATCH
DBWR_COUNT=8
DBWR_BUFFER_SIZE=16M
# TPC-C配置
newOrderWeight=45
paymentWeight=43
orderStatusWeight=4
deliveryWeight=4
stockLevelWeight=4
# 测试总结
YashanDB数据库v23.1版本共享集群部署在Linux系统上性能稳定,tpmC (NewOrders)值达到183W。
| 仓数 | 并发数 | 测试时长 | tpmC (NewOrders) |
|---|---|---|---|
| 1000 | 700 | 10分钟 | 183W |
# YashanDB数据库分布式部署的TPC-H性能测试
# 硬件环境
| IP | 内存 | 磁盘空间 | 磁盘类型 | CPU | 操作系统 |
|---|---|---|---|---|---|
| 虚拟机IP地址: 192.168.8.107 192.168.8.108 192.168.8.109 192.168.8.110 物理机环境:华为2288,虚拟出4个VM,物理机关闭NUMA | 64G * 1 | 1T * 1 RAID0 IO能力:bs=1M 测试数据量10G下,写速度分别为788MB/s bs=1M 测试数据量10G下,读速度分别为1.2GB/s | SSD | Intel(R) Xeon(R) Gold 5320 CPU @ 2.20GHz * 16CPU跟VM绑定 | CentOS Linux release 7.9.2009 (Core) |
# 组网拓扑
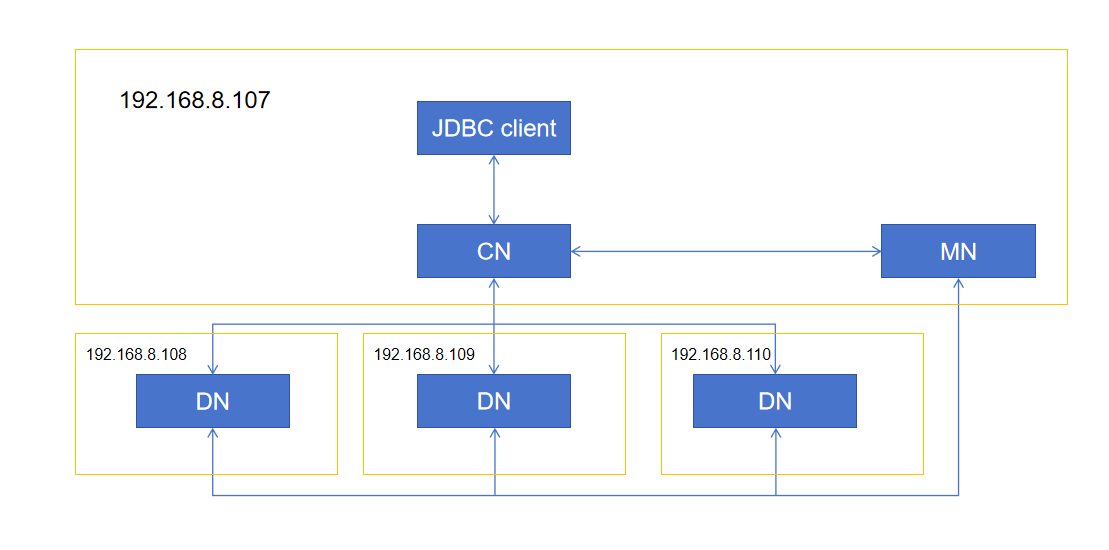
# 数据库参数配置
MAX_PARALLEL_WORKERS = 128
DEGREE_OF_PARALLEL = 16
DATA_BUFFER_SIZE = 30G
VM_BUFFER_SIZE = 20G
SCOL_DATA_BUFFER_SIZE = 1G
COLUMNAR_VM_BUFFER_SIZE = 15G
COLUMNAR_MAX_SORT_MEM = 2G
COLUMNAR_MAX_JOIN_MEM = 10G
COLUMNAR_WORK_AREA_HEAP_SIZE = 2G
UNDO_RETENTION = 5
UNDO_SHRINK_INTERVAL = 3600
DBWR_COUNT = 4
DBWR_BUFFER_SIZE = 32M
CHECKPOINT_TIMEOUT = 600
CHECKPOINT_INTERVAL = 4G
COMPRESSION = LZ4
LARGE_POOL_SIZE = 4G
PQ_POOL_SIZE = 6G
# 测试总结
YashanDB数据库v23.1版本分布式部署在如上环境配置上,使用TPC-H标准模型100G数据,按Q1-Q22顺序执行查询语句取平均值。
| TPCH | YashanDB统计结果(s) |
|---|---|
| Q1 | 1.234 |
| Q2 | 0.561 |
| Q3 | 0.998 |
| Q4 | 0.364 |
| Q5 | 1.181 |
| Q6 | 0.079 |
| Q7 | 0.958 |
| Q8 | 0.784 |
| Q9 | 3.182 |
| Q10 | 2.374 |
| Q11 | 0.348 |
| Q12 | 0.309 |
| Q13 | 2.991 |
| Q14 | 0.357 |
| Q15 | 0.890 |
| Q16 | 0.965 |
| Q17 | 0.564 |
| Q18 | 4.200 |
| Q19 | 0.413 |
| Q20 | 0.369 |
| Q21 | 1.784 |
| Q22 | 0.507 |
| 合计 | 25.415 |
# 版本约束
| 约束项 | 产品形态 |
|---|---|
| 过程体内变量与过程体内SQL语句中的列别名名称不能相同 | 单机、共享集群 |
| ST_Transform函数对不同椭球体和基准面的两个空间参考做坐标转换时,可能存在误差 | 单机 |
| 物化视图仅在SQL文本与物化视图定义匹配时才会用于查询改写 | 单机 |
| DBLink连接Oracle,从远端返回的错误消息,YashanDB最多只输出1024字节 | 单机 |
| ST_GeomFromText函数当输入的坐标是4维时,只会解析前3维坐标,第4维坐标会被忽略 | 单机 |
 下载文档
下载文档
 复制链接
复制链接