
#分布式
YashanDB分布式部署基于Shared-Nothing 架构,由多个节点组(Coordinator Node Group、Management Node Group、Data Node Group)组成,节点组内有多个节点(Coordinator Node、Management Node、Data Node)。这些节点部署在不同主机上,有不同的安装目录、数据目录,并且通过一些网络端口进行内部通讯或对外提供服务。 以下为一个典型的分布式部署示意图:
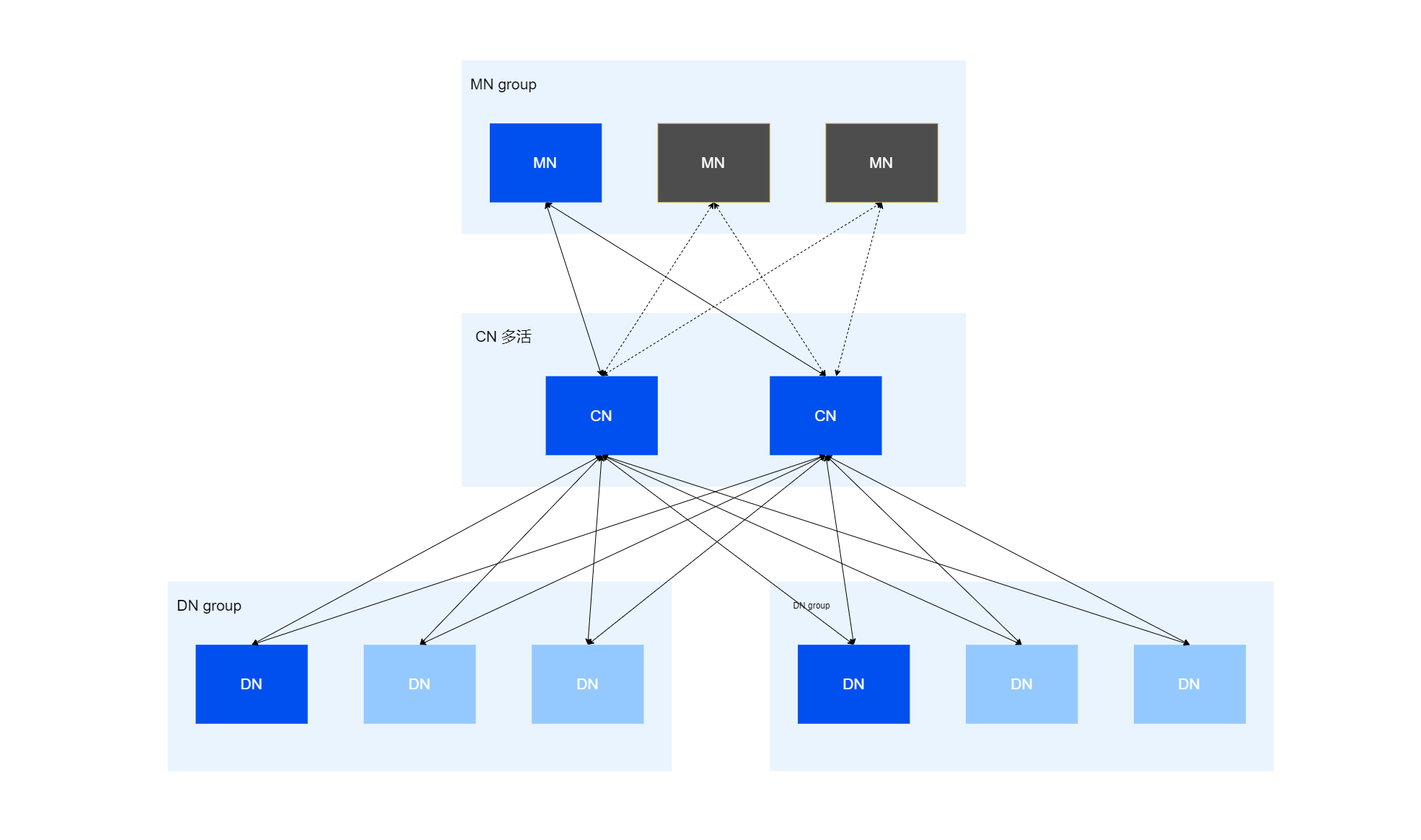
MN group
管理节点组,组内包含一个主机和多个备机,主机提供当前在线服务,读写模式,备机从主机接收日志并回放,只读模式,主机故障时从备机状态切换为主机状态。
CN多活
协调节点组,组内包含多个主机,均提供在线服务且支持负载均衡,当某个主机出现异常时,由其他主机继续提供服务。
DN group
数据节点组,组内包含一个主机和多个备机,主机提供当前在线服务,读写模式,备机从主机接收日志并回放,只读模式,主机故障时从备机状态切换为主机状态。
# 分布式数据空间管理
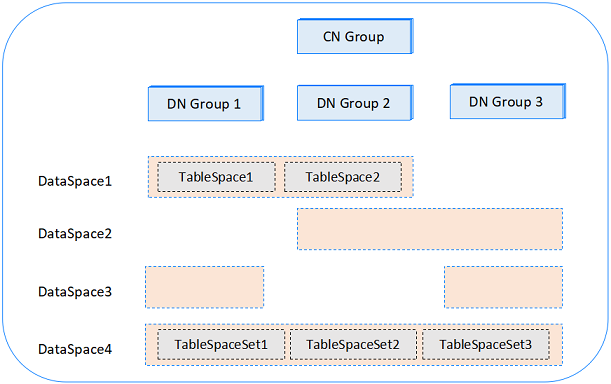
分布式数据空间管理提供切分数据的能力,用户可以选择合适的策略将数据切分到不同数据空间和不同节点上,对数据与资源进行隔离。其示意图如下:
 `
`
DataSpace
分布式数据的逻辑空间,用于关联数据库与数据节点之间的关系,在创建一个DataSpace时,需要指定其关联的节点组和Chunk的个数,系统自动计算Chunk在节点组中的分布。
TableSpaceSet
用于存储分布表(Sharded Table)的表空间集,创建表空间集时,系统会自动在DataSpace关联的节点组上创建对应的表空间。
用户在创建分布表时,需要指定其所在的表空间集,或者使用默认的表空间集。表数据将依据Chunk分布到不同的节点组中。
TableSpace
用于存储复制表(Duplicated Table)的表空间,表空间会在DataSpace关联的所有节点组上创建。
用户在创建复制表时,需要指定其所在的表空间,或者使用默认的表空间。表数据将依据Chunk完全复制到不同的节点组中。
如下为用于存储分布表的DataSpace4在各节点组上分布的数据空间示意图:
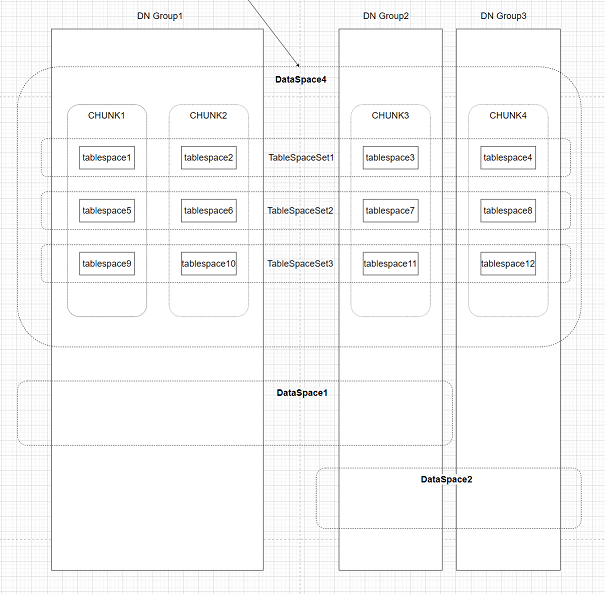
Chunk
数据分片与迁移的最小逻辑单元,一个TableSpaceSet下的一个Chunk有且仅有一个tablespace。
tablespace
数据表空间,数据分片与迁移的最小物理单元。
# 默认数据空间
为简化存储管理,YashanDB在安装过程中内置了创建DataSpace和TableSpaceSet的脚本,作为默认的数据空间,用户建表时无需进行指定,即可按默认规则将数据分布到各DN组上。
# 分布式SQL执行过程
在一个分布式SQL的执行过程中,主要有如下两类实例参与:
协调实例(CN):负责对外提供接口,接收用户请求,生成分布式执行计划,向DN分发查询计划进行执行并汇总执行结果。
数据实例(DN):负责存储数据,并行执行CN下发的执行计划 。
分布式SQL引擎将用户文本形式的SQL语句进行解析、验证、优化、CN向DN执行计划分发、CN/DN多节点并行执行,并最终返回查询结果集给用户。
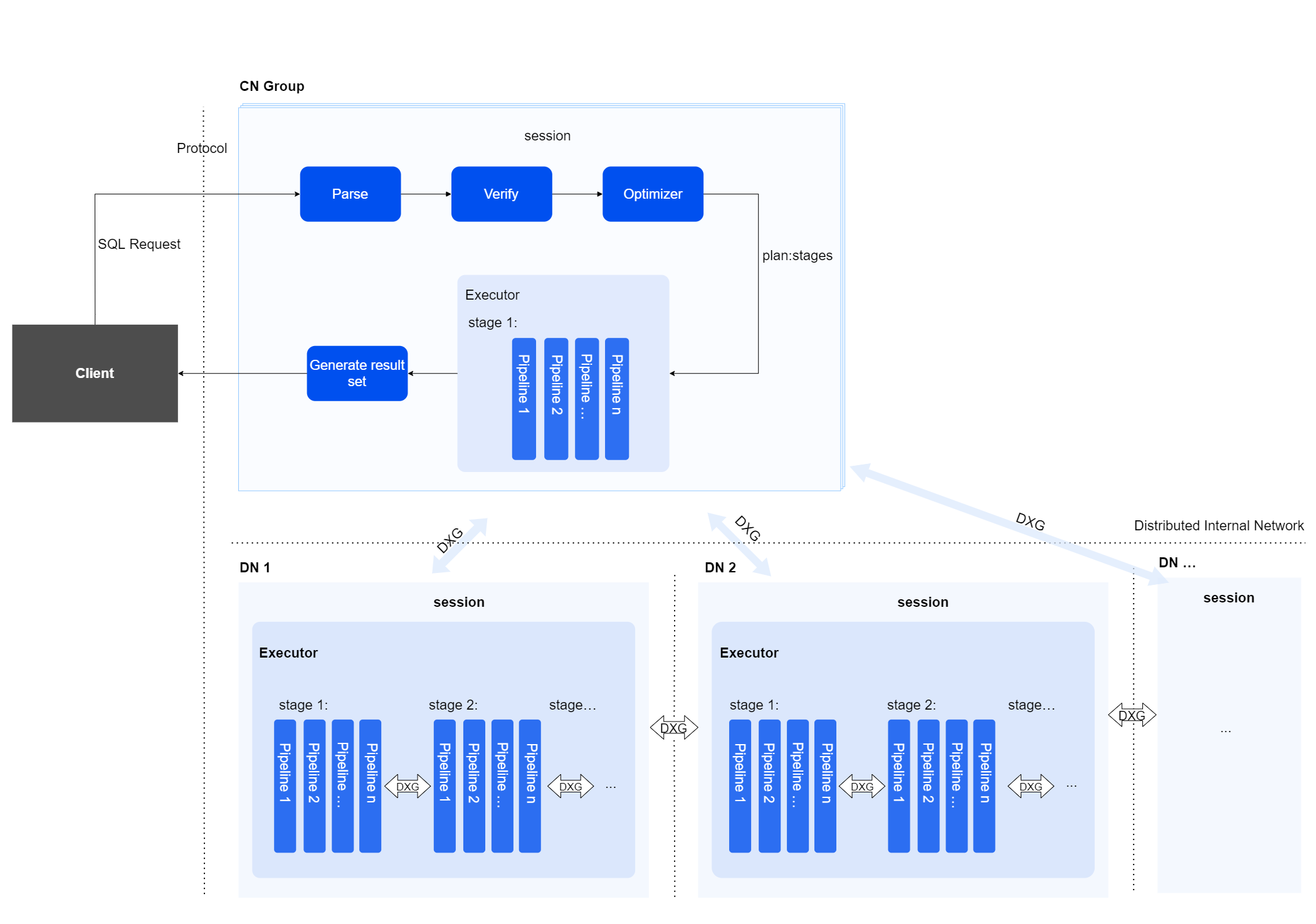
session
会话管理,用于进行节点间的管理,总管节点间执行的最终状态,以及调度节点间的执行过程。
Distributed Internal Network
采用异步网络通讯框架的分布式通信组件,负责节点之间的网络通信,包括CN向DN分发的执行计划,及各节点间的数据交换。
Parser
解析器,负责将用户输入的语句进行词法、语法、语义解析,并生成Parse Tree。解析器采用软解析,在缓存中复用,高频语句高收益。
Verifier
校验器,负责用户角色权限验证,数据合法性检测,语法约束校验等,并将优化器部分工作前置,提前对Parse Tree结构体做优化变形,减少后续环节负担,为性能加速。
Optimizer
优化器,由Parse Tree生成分布式执行计划(plan),并将其切分成可独立运行的计划片段(stages)。
Executor
执行器,负责执行plan(stages)中的算子,YashanDB的分布式SQL引擎采用多级并行执行模式,极大提升了计算效率。
pipeline
并行调度单元。
# 数据交换机制
分布式数据库里的数据分片(区)存储在不同节点上,当某一个SQL计算的数据源来自于不同片(区)时,需要由特定的PX并行执行算子,将数据按指定方式,搬运到指定位置。
在一个分布式SQL的执行过程中,可能会发生如下几种情形的数据交换:
- DN上的数据向CN上汇聚成分布式SQL的查询结果。
- CN向DN发送要插入或更新的数据。
- 某个DN上的计算需使用其他DN上的数据,需要将其他DN上的数据搬运过来。
- 某个stage向同节点内的其他stage传递数据。
# 并行执行
YashanDB的分布式SQL执行采用典型的MPP架构,分为两级:
第一级:节点间并行
CN上的优化器根据表数据的分布信息,将一个复杂查询分为多个stage,发送到不同的DN,各DN/stage之间并行执行。
第二级:节点内并行
节点内并行执行的切分方式可以分为两类:
水平切分:CN上的优化器切分后产生的stage,在DN上可以根据数据分片信息等将一个stage放到多个pipeline执行,每个pipeline处理一个区间的数据。
垂直切分:在水平切分后,资源仍有结余,仍想继续充分利用CPU多核的能力,可以继续对stage进行垂直切分,切成多份更小的stage进行并行执行。
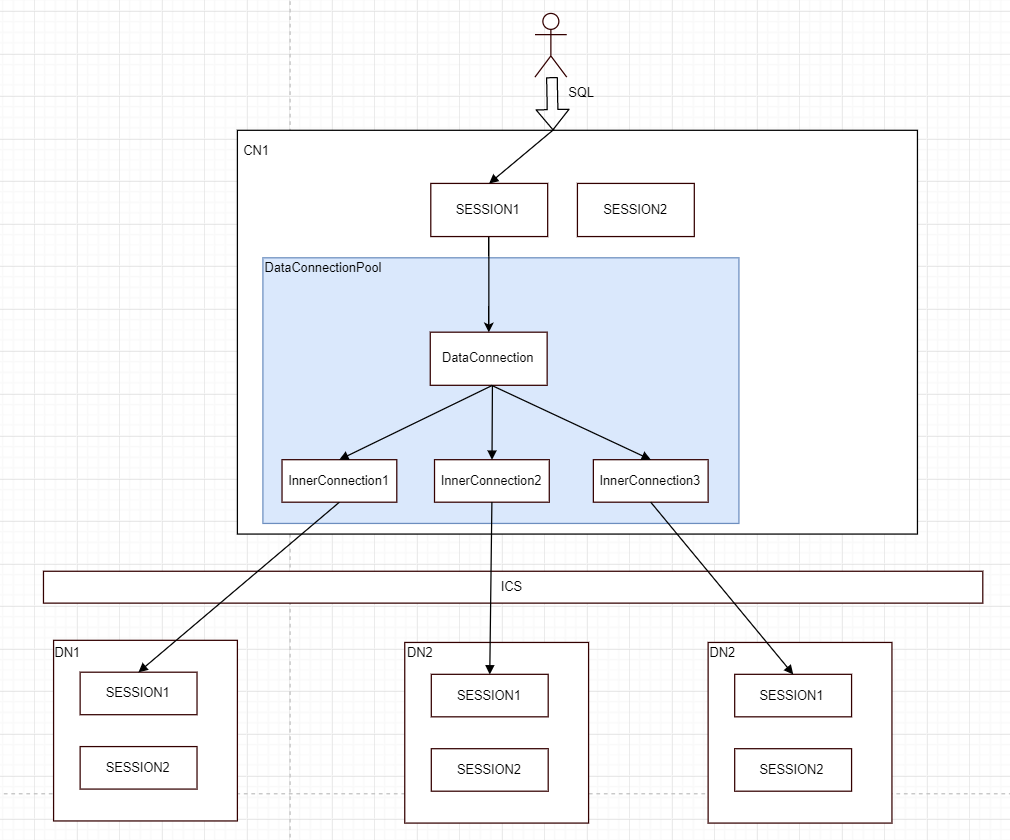
# 会话管理
数据库的会话管理被用于对应客户端的连接,并隔离不同连接间的用户操作及资源使用。
分布式部署中,会话管理总管节点间执行的最终状态,以及调度节点间的执行过程,为用户提供一套统一的接口,简化客户端操作,对用户隔离CN与DN的交互逻辑。
 下载文档
下载文档
 复制链接
复制链接