
#SQL
SQL引擎是数据库核心部件之一,YashanDB的SQL引擎内部通过紧耦合达到极致高性能,外部则与存储引擎松耦合,接口可插拔,以减少事务及快照的关联,降低编程复杂度,实现对外的快速响应。
# SQL执行过程
SQL引擎将用户文本形式的SQL语句进行解析、验证、优化、执行,并返回查询结果集给用户。
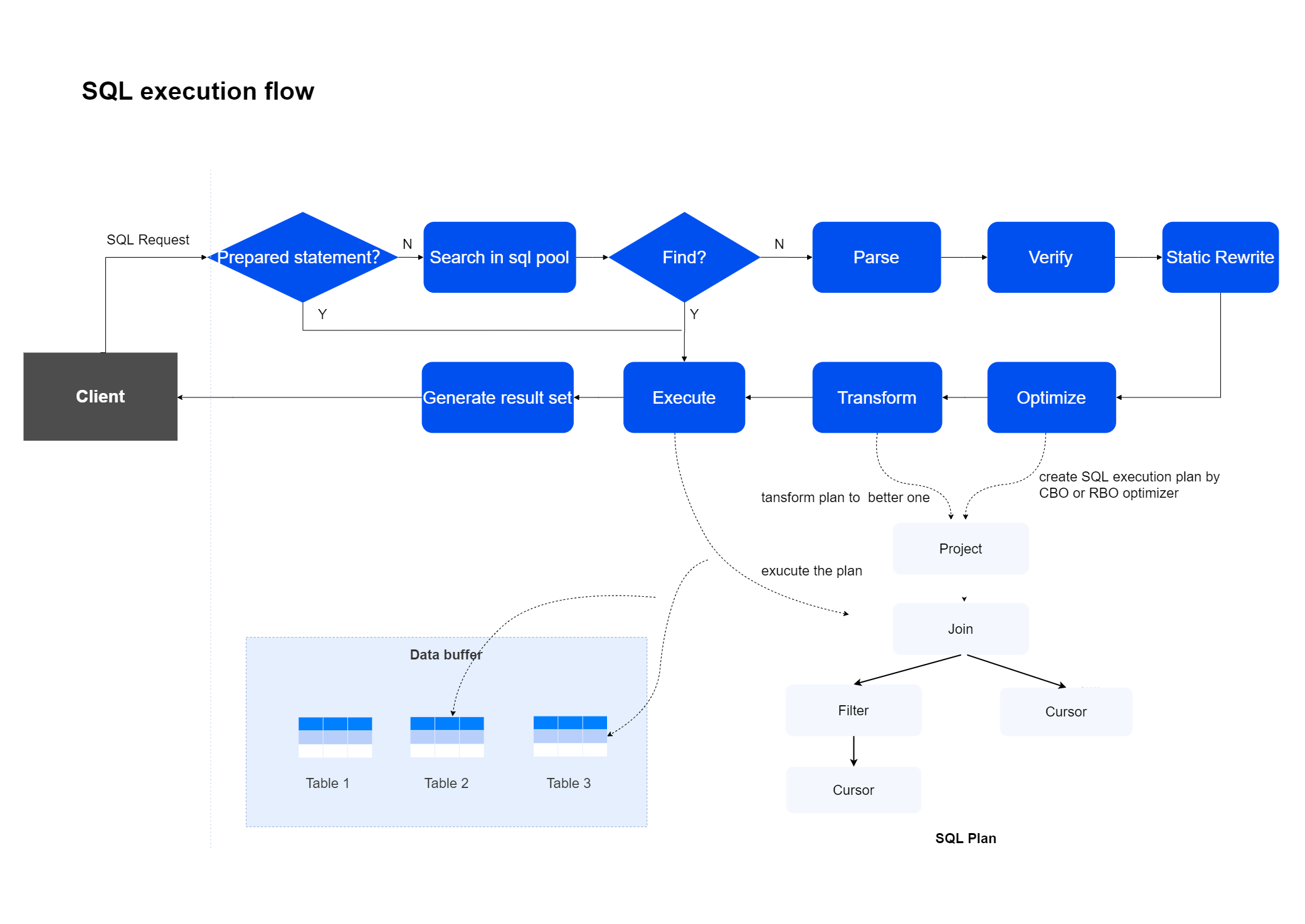
Parser
解析器,负责将用户输入的语句(支持多字符集)进行词法、语法、语义解析,并生成Parse Tree。解析器采用软解析,在缓存中复用,高频语句高收益。
Verifier
校验器,负责用户角色权限验证,数据合法性检测,语法约束校验等,并将优化器部分工作前置,提前对Parse Tree结构体做优化变形,减少后续环节负担,为性能加速。
Optimizer
优化器,由Parse Tree生成SQL execution plan,智能化的SQL引擎大脑。
Executor
执行器,负责执行SQL execution plan中的算子,支持并行计算以提升效率。
# 优化器
优化器是SQL引擎的核心部件,YashanDB的优化器采用CBO(Cost Based Optimizer)优化模式。
优化器的目标是为SQL语句生成最有效的执行计划传递给执行器,执行计划包含数据访问路径、表连接顺序等执行算子信息。YashanDB的CBO优化器基于统计信息,计算数据访问和处理所需要的代价,选择代价最低的方案生成执行计划。
统计信息
主要包括表、列、索引的统计信息,例如表的行数、列的平均长度、索引包含的列数等。统计信息有动态收集、实时收集、在线收集、定时任务及手动触发等多种收集方式,同时,可通过并行统计、抽样统计等技术加快统计效率,为优化器提供及时更新的信息。
执行算子
算子定义了某一种具体的计算操作,为执行计划的基本组成单元。YashanDB实现了如下几类基本算子:
- 扫描算子
- 表连接算子
- 查询算子
- 排序算子
- 辅助功能算子
HINT
HINT允许用户对优化器对算子的选择和执行方式提出干预,例如指定表扫描的方式、指定执行顺序、指定并行度等,优化器将根据这些提示,结合统计信息,生成最优的执行计划。
并行度
优化器基于统计信息生成最优的执行计划,有可能因为底层硬件资源(IO限制、内存限制等)的不足而表现并不佳,用户可以根据对硬件环境的观察,在可行时通过HINT指定并行度,让算子多线程并发执行,提高SQL语句执行的整体效率。
# 向量化计算引擎
YashanDB的列计算采用向量化执行模型,利用SIMD原理对某一列数据进行批量处理和计算,提高CPU利用率,大批量地减少程序循环。
向量化执行的内容包括:
- 批处理:算子间传递数据不再是一条一条记录,而是一批数据。
- 并行计算:算子并发执行。
向量化执行的计算框架包括:
- 向量:算子之间传递的数据结构,由一批连续内存存储,数据类型相同,长度已知的列数据组成。
- 表达式:通用表达式,如Literal、Column、Function、一元/二元运算等,通过建立计算表达式结构体,将其绑定执行所需的上下文信息、Schema生成已绑定可执行表达式,再进行计算。
- 执行算子:算子是SQL中将查询计划具体执行的功能单位,将输入的向量数据进行处理然后输出结果向量数据。
 下载文档
下载文档
 复制链接
复制链接