
#存储
存储引擎是数据库核心部件之一,YashanDB通过不同的存储引擎适应不同的应用场景,以获得面向在线交易场景的高效事务处理能力,面向实时分析场景的事务与分析均衡能力,和面向海量稳态数据分析场景的高性能。
基于不同的存储引擎,YashanDB支持的表类型有HEAP表,TAC表和LSC表。
HEAP Table:行存表,主打OLTP场景。
TAC Table (Transaction Analytics Columnar Table) :列存表,主打实时分析场景。
LSC Table (Large-scale Storage Columnar Table):列存表,主打海量稳态数据的交互式分析场景。
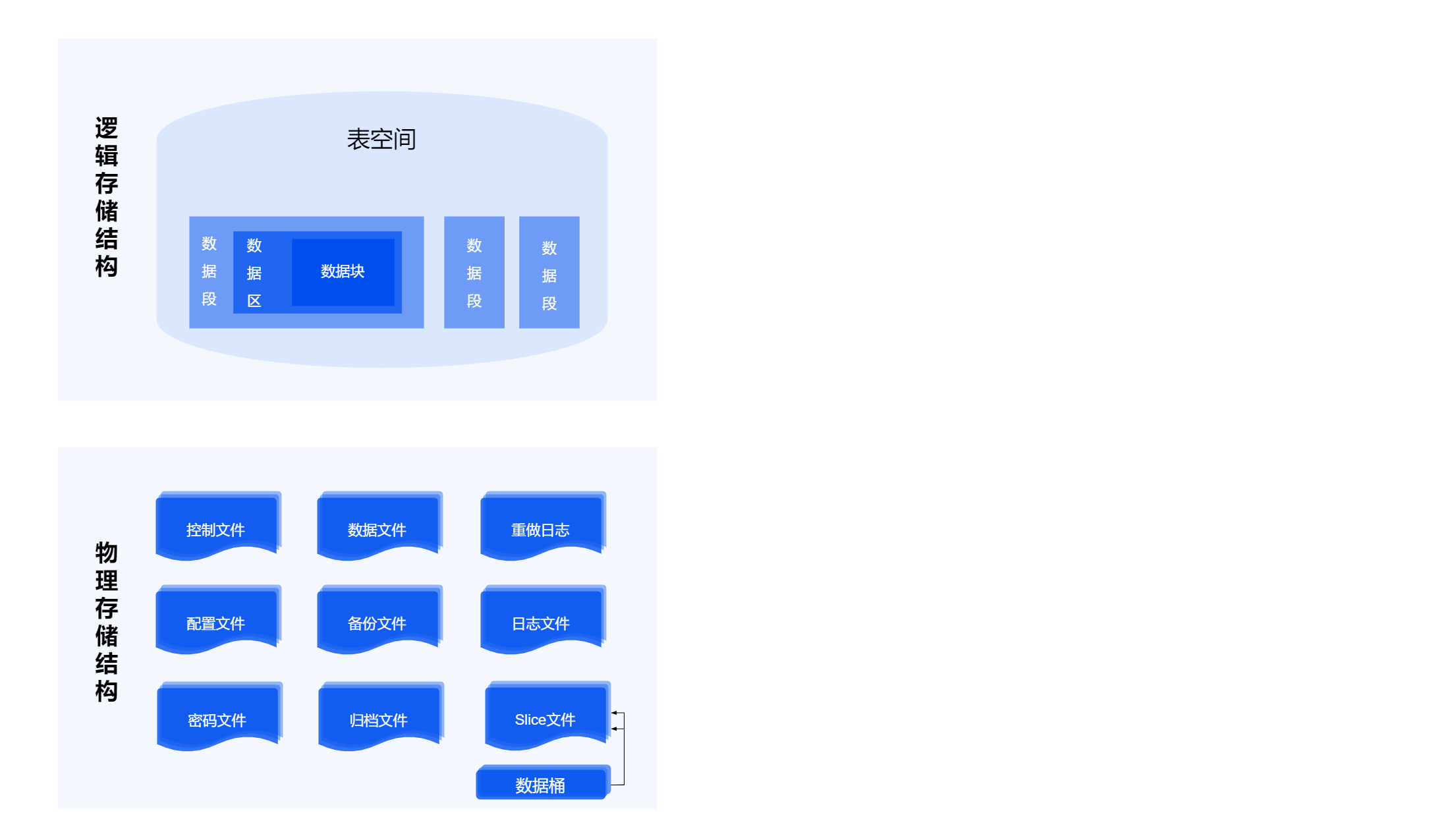
YashanDB将数据库的存储空间划分为若干表空间,表空间之间互相隔离。 每个表空间采用段页式或者对象式(用于LSC稳态数据)管理存储空间。
所有的段页式表空间均包含数据段、索引段、回滚段等不同类型的段,每种段采用数据区和数据块的方式管理空间,使得空间使用更加灵活,管理更加高效,使用率更高。
# HEAP存储架构
为实现事务的ACID,YashanDB对HEAP表采用了段页式的存储管理,和Checkpoint+redo的持久化机制,并提供堆表、B+树索引等基本的数据结构,且堆表和B+树索引均实现了MVCC多版本能力,可以保证一致性读和一致性写。

Tablespace
表空间,可以给表、索引实体对象分配空间的容器。
Datafile
数据文件,一组数据文件组成一个Tablespace,在Tablespace空间不足时,可以扩展数据文件的大小,或者增加新的数据文件。
Segment
数据段,数据库中的表、索引等对象实体,都通过Segment来承载。
Extent
数据区,Segment从Tablespace申请空间时,最小粒度就是一个Extent,一般包括若干个Block。YashanDB使用Extent Map对Segment内的Extent进行管理。
Block
数据块,数据库的数据是按Block来组织的,数据需要持久化时,Block是最小的磁盘IO单位。
Row
数据行,用户增删改查操作的记录,存储时按Row的格式组织。Row格式里描述了每个列字段的长度,支撑包含变长列(VARCHAR、LOB等)字段的数据行存储。
# TAC存储架构
TAC表数据存储在支持实时业务的可变列式存储区,每个列的数据集中存储,并实现in-place update,提升列查询速度下,又可实现快速更新;可变列式存储区采用段页式管理(MCOL格式),最小访问数据单元为Block。
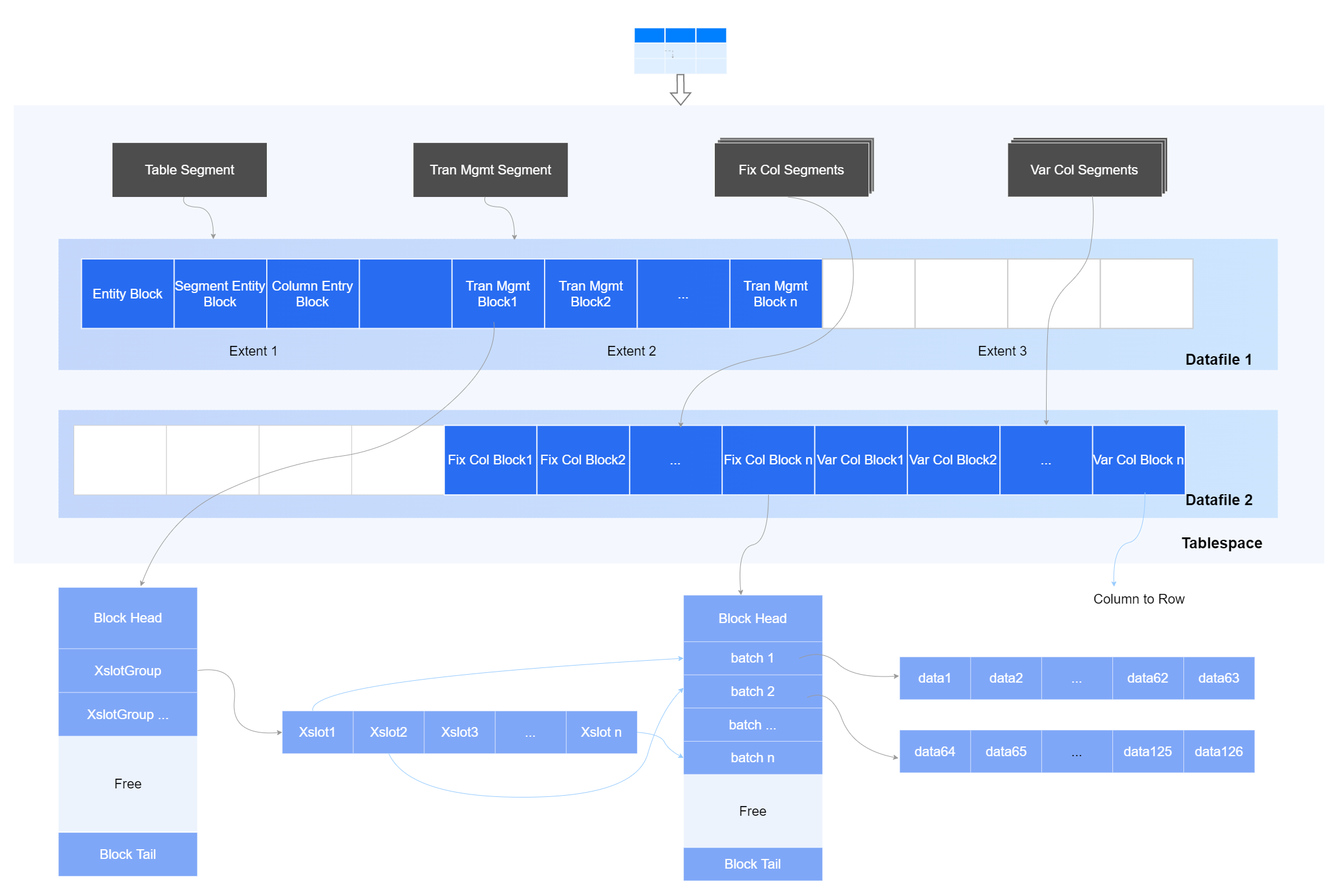
Tablespace
表空间,可以给表、索引实体对象分配空间的容器。
Datafile
数据文件,一组数据文件组成一个Tablespace,在Tablespace空间不足时,可以扩展数据文件的大小,或者增加新的数据文件。
Segment
数据库中,表、索引等对象实体,以及列存表的每个列,都是通过Segment来承载。
Extent
Segment从Tablespace申请空间时,最小粒度就是一个Extent,一般一个Extent包括若干个Block。
Block
数据库的数据是按Block来组织的,数据需要持久化时,Block是最小的磁盘IO单位。通常数据库的Block大小与操作系统的Block大小为倍数关系,YashanDB默认Block大小为8K。
Batch
列存存储按列格式来组织,每个列的一批记录组成一个Batch,作为数据读取的基本单位。
Table/Partition Segment
记录TAC表的总体入口信息。
- Entry Block:入口Block,记录TAC表的相关统计信息、Slice的空闲位图及辅助信息。
- Segment Entry Block:记录表按列逻辑分割后的所有Segment信息。
- Column Entry Block:记录所有列的元数据信息。
Tran Mgmt Segment
事务管理段,通过Segment中的Xslot管理各Fix Col Block和Var Col Block上执行的事务,保证数据写入的事务一致性。
Fix Col Segment
每一个定长列独立划分为一个Segment,内部包含若干Block。
Var Col Segment
针对变长列,将进行列转行存储,支撑变长列的事务处理能力。
# LSC存储架构
LSC表数据在写入时存储在可支持实时业务的可变列式存储区,以适应业务写入的实时性,并依据特定规则在后台转换到稳态数据区,稳态数据通过数据排序,稀疏索引,下推过滤等实现海量数据的高性能查询。数据的后台转换对业务层的查询请求透明,查询请求可分别从实时数据区和稳态数据区获取数据做合并,并满足事务要求。

可变列式存储区和稳态数据区的数据均按照表或分区进行组织,对应着Active Slices和Stable Slices两部分,其中Active Slices采用段页式存储(MCOL格式),Stable Slices采用对象存储( SCOL格式 )。访问数据时,根据Entry Block查询到表数据组织情况,再通过对应的Slices进行下一级数据扫描。

Tablespace:可以给表数据分配空间的容器。
Table/Partion Segment:记录表的总体入口信息。
- Entry Block:入口Block,记录表数据的Slice分布情况、统计信息及辅助信息。
- Active Slice Entry:记录Active Slice元数据信息。
- Stable Slice Entry:记录Stable Slice元数据信息。
Active Slice:记录可变数据的信息,当可变数据达到阈值后将自动转为稳态数据。
- Segment Entry Block:记录Slice内按列逻辑分割后的所有Segment信息。
- Column Entry Block:记录所有列的元数据信息。
- Tran Mgmt Segment:事务管理段,通过Segment中的Xslot管理各Fix Col Block和Var Col Block上执行的事务,保证数据写入的事务一致性。
- Fix Col Segment:每一个定长列独立划分为一个Segment,内部包含若干Block。
- Var Col Segment:针对变长列,将进行列转行进行存储,支撑变长列的事务处理能力。
Stable Slice:记录稳态数据信息。
- Row group:Stable数据先进行分组,分组后再按列进行拆分,查询时根据Slice、Row group、Column的元数据信息完成所有数据的快速定位扫描。
- Column extent:每个数据分组按列切割,通过Column extent和Block的顺序进行组织存储。Column extent作为最小IO单元和压缩单元在列式访问中尽可能利用IO能力。
在计算过程中,通过背景线程转换、并行计算、排序、条件下推、稀疏索引、IO优化、压缩等技术完成数据的高效存储、扫描。
- Transform in backgroup:支持分批次进行可变/稳态数据自动转换,数据写入时以Active Slice结构支撑快速导入以及新鲜可变数据的高效扫描;数据稳定后通过背景线程分批转换为Stable Slice存储。
- Parallel Execution:Slice级别的并行计算。
- Sorting Data:Row group内和Row group间支持数据排序,提高数据的扫描速度。
- Filter Pushdown:支持Slice和Row group级别的过滤下推,减少数据的内存加载次数。
- IO suitable Unit:Row group内,每列Column extent将考虑磁盘连续扫描情况进行数据就近存储优化,减少磁盘IO读。
- Compression Unit:Row group内,数据进行独立存储后,通过压缩算法减少存储空间消耗。
# 变长列存储结构
# 行式变长列存储
在update某一个行式变长列字段时,系统采取如下几种不同的存储方式:
in-place update
列字段长度在更新前后未发生变化,可以定位到改列字段位置,直接进行数据替换(与定长列字段处理方式一致)。

in-page update
列字段长度在更新后变小时,将行变短,在原位置重组行;变大时,将行变长,页面free空间足够时在本页面重组行。

行迁移与行链接
列字段长度在更新后变大时,将行变长,且页面free空间不足够在本页面重组行,此时该行数据将被完整迁移到其他的页面。
当变长的行超过了整个页面能容纳的大小时,该行数据将被拆分到多个页面存储,且多个页面通过链接以标识一个行。

# 列式变长列存储
YashanDB对列式变长字段(如LOB、VARCHAR等)的存储采用行列结合技术,每列单独拥有一个Heap Segment,每列每一行数据采用一个Row存储,如下所示:

变长字段的数据存储沿用YashanDB的Heap行存机制,实现对列式数据的高效删改,同时,通过Rowid逻辑映射结构实现行列对应和Batch分批事务处理,保持列式数据的批量增查优势。
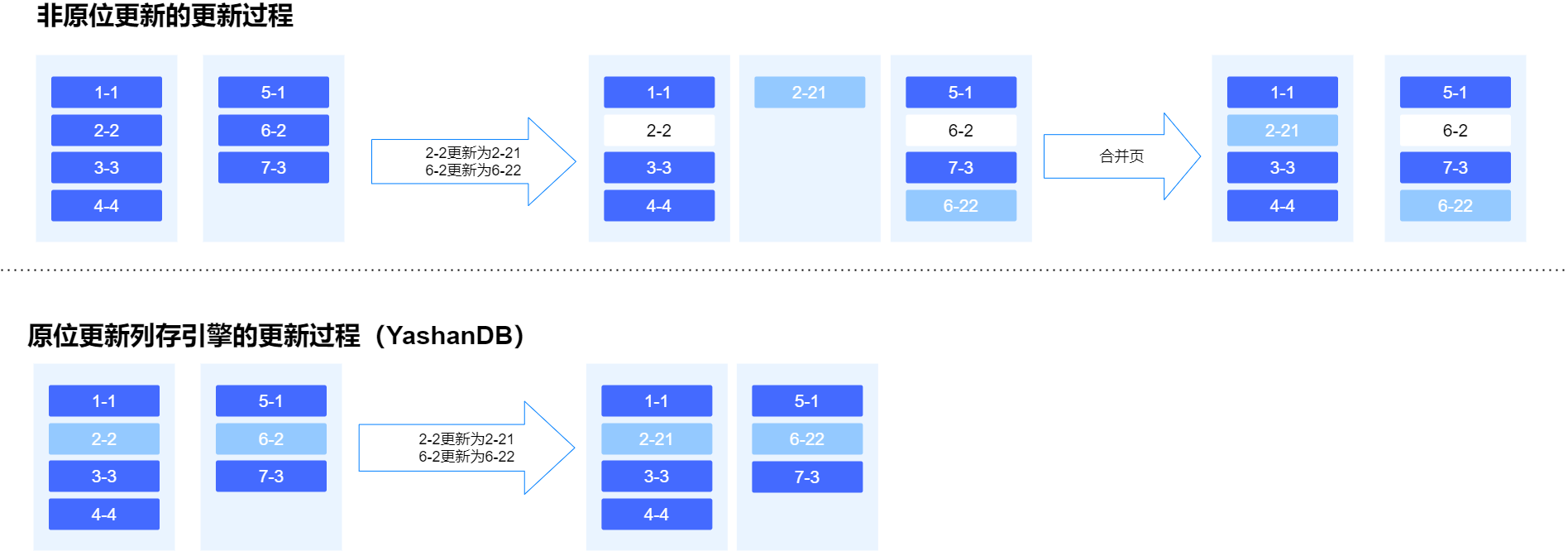
# 原位更新
传统的分析型数据库采用列式存储时,对插入和更新都是在末端插入一个新值,并标记被替代的数据。YashanDB与之不同的是实现了原位更新(in-place update),这样的好处是避免在存储区域产生"墓碑",避免空间膨胀与垃圾扫描,极大地提升存储和检索数据的效率。
# 持久化
持久化即将段页式逻辑结构的内存数据按物理结构落盘,永久化保存。
redo
在数据库中对数据的修改都必须记录redo重做日志,用于故障恢复,主备复制等,YashanDB采用WAL(Write Ahead Log)机制,对数据修改操作先记录redo,批量落盘,以减少直接将数据落盘对IO性能的影响。
Checkpoint
内存中修改的数据不会直接落盘,而是由YashanDB的Checkpoint机制来完成,这些数据基于redo记录的顺序被加入到队列中,当Checkpoint被触发时,写进程将执行读取数据并插入到数据文件中,同时更新队列和释放redo空间。
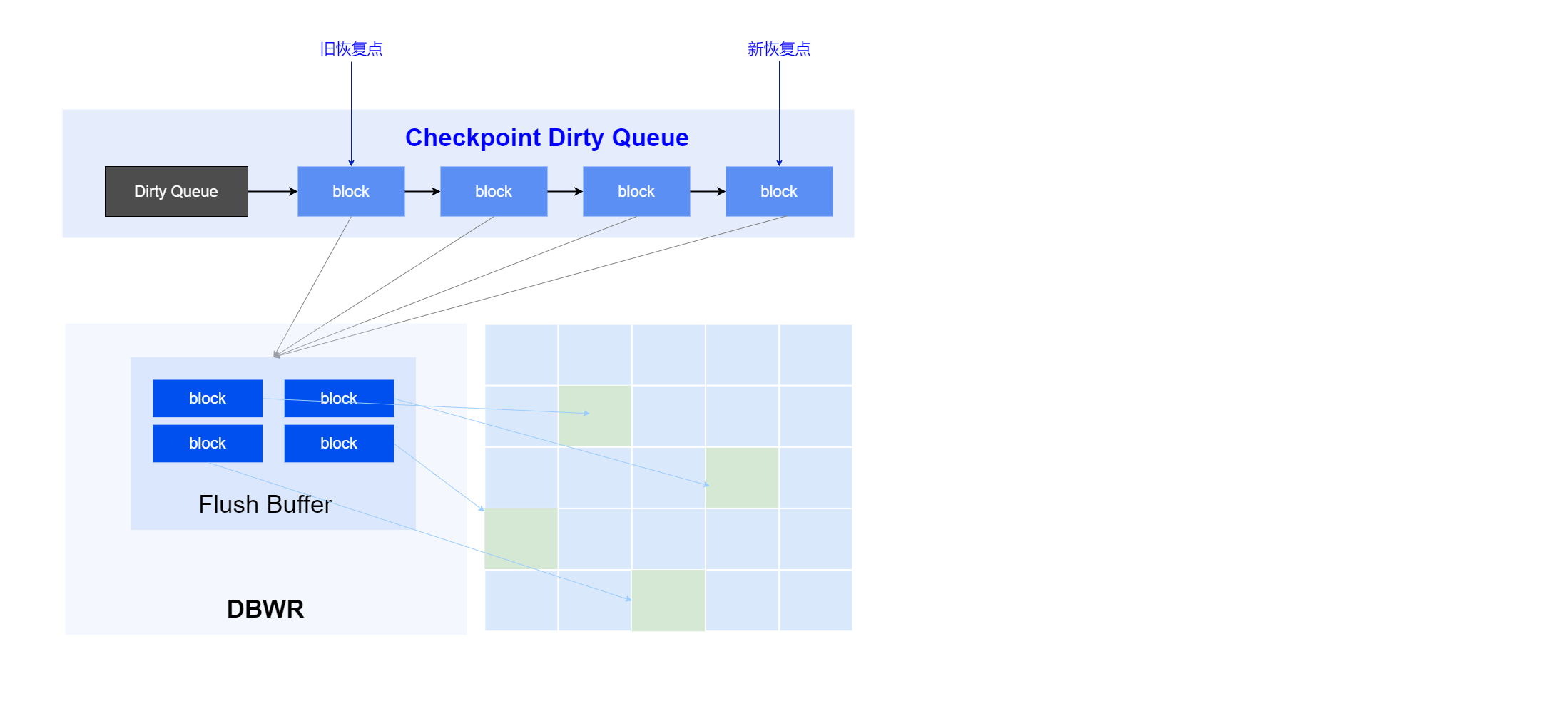
系统采取多线程写、IO合并、IO排序等优化手段提升落盘效率。同时,YashanDB引入双写机制,避免在服务器掉电等意外场景下可能出现的半写问题,严格保证数据完整性。
SCOL storage
LSC表的MCOL格式数据在通过背景线程的转换压缩后,会变成SCOL格式,持久化存储到对应的数据桶(DataBucket,对象存储路径,DataBucket支持指定本地磁盘或云端存储),数据桶中包含存放数据的切片(Slice)文件。
 下载文档
下载文档
 复制链接
复制链接